Cette page sert de carnet de bord vivant pour les sujets que je teste, maintiens ou veux documenter.
Elle n’est pas une roadmap figée. Certains chantiers sont déjà en production dans mon usage perso, d’autres sont encore au stade “à tester proprement avant d’en parler”. L’idée est de garder une trace de ce qui bouge dans le lab, avant que ça devienne éventuellement un article complet.
Socle homelab#
![]()
Le coeur du lab reste une base simple : quelques machines, des VM, des conteneurs, du réseau interne, des sauvegardes et assez de séparation pour pouvoir casser des choses sans tout casser.
Proxmox#
Proxmox est le socle principal pour organiser les essais longue durée.
Ce que je veux documenter plus proprement :
- la séparation entre VM, conteneurs LXC et services exposés ;
- les snapshots utiles, et ceux qui donnent une fausse impression de sécurité ;
- les sauvegardes réellement restaurables ;
- le réseau interne, les bridges, les VLAN et les flux entre services ;
- les petites habitudes qui rendent un homelab maintenable dans le temps.
L’objectif n’est pas de faire une architecture parfaite. C’est plutôt de garder un lab lisible, reproductible, et assez robuste pour tester sans repartir de zéro à chaque erreur.
VPS low-cost#
Les petits VPS restent un bon terrain de jeu. Ils obligent à choisir : peu de RAM, peu de CPU, parfois peu d’IO, mais assez pour apprendre beaucoup.
Ce que je continue à tester :
- services utiles sur petites machines ;
- monitoring léger ;
- reverse proxy et exposition minimale ;
- sauvegardes hors serveur ;
- limites réelles des offres à très bas coût.
Docker vers Kubernetes#
Une autre piste importante du lab : migrer progressivement une partie des services aujourd’hui gérés avec Docker Compose vers Kubernetes.
Je ne veux pas faire une migration “parce que Kubernetes”. Le but est de comprendre où Kubernetes apporte vraiment quelque chose dans mon contexte, et où Docker Compose reste plus simple, plus lisible et largement suffisant.
Ce que je veux tester :
- transformer quelques stacks Compose en manifests Kubernetes propres ;
- comparer k3s, Talos ou une autre approche légère pour homelab ;
- gérer les secrets sans bricolage dangereux ;
- exposer les services avec Ingress, certificats et DNS interne ;
- connecter ça proprement à Proxmox, au stockage et aux sauvegardes ;
- mesurer la complexité ajoutée par rapport au gain réel.
Le bon résultat ne sera pas forcément “tout migrer”. Ce sera plutôt une cartographie claire : ce qui reste en Docker, ce qui passe en Kubernetes, et pourquoi.
Sortir progressivement de Cloudflare#
![]()
Je veux explorer une sortie progressive de Cloudflare, sans faire semblant que tout se remplace en une soirée.
Cloudflare rend beaucoup de choses confortables : DNS, proxy, TLS, redirections, règles de sécurité, cache, protection basique. Le but n’est pas de tout jeter par principe, mais de comprendre précisément ce que j’utilise, ce que je peux reprendre en main, et ce que je préfère éventuellement garder ailleurs.
Knot DNS#
Knot DNS m’intéresse comme serveur DNS autoritaire pour reprendre la main sur une partie de la chaîne DNS.
Les points que je veux tester :
- héberger une zone autoritaire propre ;
- gérer les enregistrements sans interface magique ;
- comprendre la délégation et les glue records dans un cas réel ;
- tester DNSSEC sans transformer le lab en usine à stress ;
- monitorer la disponibilité DNS depuis l’extérieur ;
- documenter une procédure de rollback si le DNS part de travers.
Le vrai sujet n’est pas seulement “installer Knot”. Le sujet, c’est : jusqu’où peut-on reprendre le contrôle du DNS sans perdre en fiabilité ?
Ce qu’il faudra remplacer ou accepter#
Quitter Cloudflare veut dire lister les dépendances une par une :
- DNS autoritaire ;
- proxy HTTP ;
- terminaison TLS ;
- protection contre trafic automatisé ;
- règles de filtrage ;
- redirections ;
- logs et visibilité ;
- confort d’exploitation.
Si une brique reste chez un fournisseur externe, ce n’est pas forcément un échec. Mais je veux que ce soit un choix clair, pas une dépendance oubliée.
Protection web et crawlers#

Anubis m’intéresse pour une raison très concrète : les petits sites prennent de plus en plus de trafic automatisé, parfois sans avoir l’infra ou l’envie de mettre un gros CDN devant.
Anubis#
Je veux tester Anubis comme couche de protection devant certains services web, notamment dans un scénario où Cloudflare n’est plus le réflexe par défaut.
Les questions à vérifier :
- est-ce que l’expérience reste acceptable pour un vrai lecteur ?
- quels crawlers sont bloqués ou ralentis ?
- comment gérer les bons bots : moteurs de recherche, archives, flux RSS ?
- où placer Anubis : devant Hugo, devant Pangolin, ou devant certains services seulement ?
- quels logs garder pour comprendre ce qui se passe sans collecter n’importe quoi ?
- comment éviter de rendre le site fragile ou pénible ?
Je ne veux pas juste “mettre une protection”. Je veux comprendre le compromis entre autonomie, accessibilité, SEO, archivage et tranquillité côté serveur.
Services exposés#
Pangolin + CrowdSec Manager#
Pangolin reste un gros morceau du lab : exposition de services, accès privés, SSO, ressources publiques et maintenance.
Ce qui mérite encore des articles :
- architecture Pangolin propre ;
- ressources publiques vs privées ;
- accès interne via Newt ;
- exposition de dashboards sans port public ;
- intégration CrowdSec ;
- workflows de mise à jour.
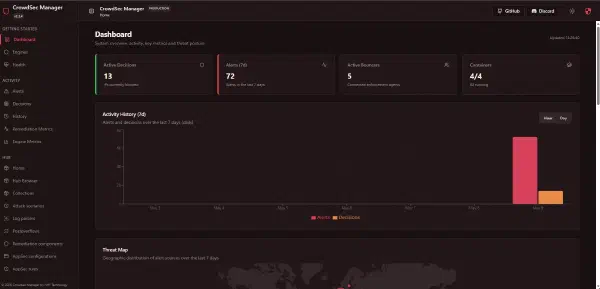
CrowdSec Manager est utile parce qu’il rend la supervision plus concrète : alertes, décisions, bouncers, faux positifs, remédiations. Il faut maintenant documenter les usages du quotidien, pas seulement l’installation.
Docker, Kubernetes et exposition#
La migration Docker vers Kubernetes devra aussi répondre à une question très concrète : comment exposer proprement les services sans multiplier les couches incompréhensibles.
Les points à clarifier :
- quels services restent derrière Pangolin ;
- quels services passent par un Ingress Kubernetes ;
- comment gérer les certificats ;
- comment éviter les doubles reverse proxies inutiles ;
- comment garder des logs exploitables ;
- comment restaurer vite si un cluster devient instable.
Réseau homelab#
Le réseau est souvent la partie invisible du lab, alors que c’est elle qui décide si tout reste compréhensible.
À documenter :
- plan d’adressage ;
- DNS interne ;
- VLAN ;
- reverse proxies ;
- dépendances entre VM, conteneurs et machines physiques ;
- accès d’administration ;
- chemins de secours quand le proxy ou le DNS tombe.
Publication et contenu#
Cryptolab.re#
Le blog lui-même fait partie du lab.
Chantiers en cours ou à reprendre :
- recherche statique avec Pagefind ;
- amélioration progressive des métadonnées ;
- images plus légères ;
- séries d’articles plus visibles ;
- pages de suivi comme celle-ci ;
- vérification régulière des liens externes.
Gitea vers Forgejo#
J’utilise déjà Gitea dans mon écosystème, notamment pour l’hébergement de code et les automatisations de déploiement.
Forgejo fait partie des pistes à étudier pour voir si une migration aurait du sens dans mon contexte.
Les points à comparer :
- compatibilité avec les dépôts existants ;
- migration des issues, releases, utilisateurs et organisations ;
- compatibilité des workflows Gitea Actions ;
- intégration avec les déploiements actuels ;
- sauvegardes et restauration ;
- rythme de maintenance ;
- gouvernance du projet et alignement avec l’esprit self-hosting.
Le but n’est pas de migrer pour changer de logo. Le vrai sujet, c’est de savoir quelle forge Git est la plus saine à maintenir dans le temps pour un petit lab auto-hébergé.
Veille open source#
Je veux garder une veille utile, pas une pile de favoris jamais testés.
La méthode que je veux conserver :
- repérer les projets intéressants ;
- noter pourquoi ils m’intéressent ;
- tester petit ;
- documenter ce qui marche ;
- documenter aussi ce qui ne vaut pas l’effort.
Sources des visuels#
- Logo Proxmox : Wikimedia Commons, fichier
Logo Proxmox.svg. - Logo Knot DNS : site officiel
knot-dns.cz. - Visuel Anubis : dépôt GitHub
TecharoHQ/anubis.
Notes#
Cette page bougera avec les essais, les abandons, les trouvailles et les articles à venir.
Si un sujet apparaît ici longtemps sans article, c’est probablement qu’il est encore en train de casser quelque chose dans un coin du lab.